Document Extraction looks for appropriately named signatures and fields in an uploaded PDF document, and for each one, it creates a OneSpan Sign signature or field. The positions and sizes of the signatures and fields from the PDF are automatically retained in OneSpan Sign.
The information needed to create each OneSpan Sign signature or field is taken from the name of the PDF signature or field.
Document Extraction Limitations
The following limitations affect Document Extraction:
-
Document Extraction is available only in the API call that uploads the document. It is not available in subsequent calls.
-
The following fields are not supported when using Document Extraction.
-
Radio buttons
-
List fields
-
Date fields
-
Custom fields
-
Text area
-
Naming Conventions
To create a OneSpan Sign signature field, the PDF field must have a name of the form [Signer.SigStyle#], where:
Signer: By default, the values used for the role of the extraction tag/fieldName are Signer1, Signer2, and so on. If you want to include the sender of the transaction as a signer, use the tag Owner. If you specify a custom role ID for your recipients, you'd use that value in your tags.SigStyle#: A signature style (Capture, Initials, Fullname, or Mobile Capture) combined with an integer for uniqueness. For example: Capture1 or Fullname09.
If you want the signature field to be optional, simply use the following format: [Signer.SigStyle#.Optional].
To create an unbound OneSpan Sign field, the PDF field must have a name of the form [Signer.SigStyle#.FieldStyle#], where:
Signer.SigStyle#identifies the signature associated with this field.FieldStyle#is a field style (Textfield or Checkbox) combined with an integer for uniqueness.For example: Textfield2 or Checkbox6.
To create a bound OneSpan Sign field, the PDF field must have a name of the form [Signer.SigStyle#.label#.Binding], where:
Signer.SigStyle#identifies the signature associated with this field.label#is an identifier of the field, consisting of the word label combined with an integer for uniqueness.-
Bindingis a field style.The possible values are Date or {approval.signed}, Name or {signer.name}, Title or {signer.title}, and Company or {signer.company}.Both members of each pair signify the same field style.
All parts of a PDF field name are matched using case-insensitive matches. For example, a field named [Signer1.Fullname1.label1.Date] is treated the same as a field named [Signer1.FULLNAME1.LABEL1.DATE]. Field names are alphanumeric. They cannot contain special characters other than the underscore (_).
Example
Here is an example. Suppose a package has two signers whose custom IDs are Signer1 and Owner. Further suppose that extraction is enabled, and that a PDF is uploaded which has fields with the following names:
[Owner.Fullname1] [Owner.Fullname1.label1.Date] [Owner.Fullname1.Textfield1] [Owner.Fullname1.Checkbox1] [Owner.Fullname2.Optional]
[Signer1.Capture1][Signer1.Capture1.label1.Name][Signer1.Capture1.label2.Date][Signer1.Capture1.label3.Title][Signer1.Initials1][Signer1.Initials2]
Before signing, Owner must complete two fields:
[Owner.Fullname1.Textfield1][Owner.Fullname1.Checkbox1]
Once those fields are complete, Owner can sign [Owner.Fullname1], and [Owner.Fullname1.label1.Date] will automatically be filled with the date of signing.
Signer1 needs to sign in three places:
[Signer1.Initials1][Signer1.Initials2][Signer1.Capture1]
Once these are all signed, the remaining fields will be filled:
[Signer1.Capture1.label1.Name][Signer1.Capture1.label2.Date][Signer1.Capture1.label3.Title]
If you have specified custom IDs for the sender and the signer (for example, Agent1 and Client1), use form field names similar to the ones below and the signing flow will remain the same:
[Agent1.Fullname1] [Client1.Initials1]
Other Extraction Methods
You may also be interested in our other extraction types:
To download the full code sample see our Code Share site. The PDF used in this topic can be found here.
The document extraction feature automatically creates all signatures and fields that exist in an uploaded PDF file. The positions and sizes of the signatures and fields in the PDF file are automatically retained in OneSpan Sign.
Document Extraction Limitations
The following limitations affect Document Extraction:
-
Document Extraction is available only in the API call that uploads the document. It is not available in subsequent calls.
-
The following fields are not supported when using Document Extraction.
-
Radio buttons
-
List fields
-
Date fields
-
Custom fields
-
Text area
-
Configuring the PDF Form Fields
First, you will need a PDF with form fields, named in a way that OneSpan Sign can recognize them. For more information on the proper format of the form field names see the feature overview. The form field names on the fields are shown in the image below.
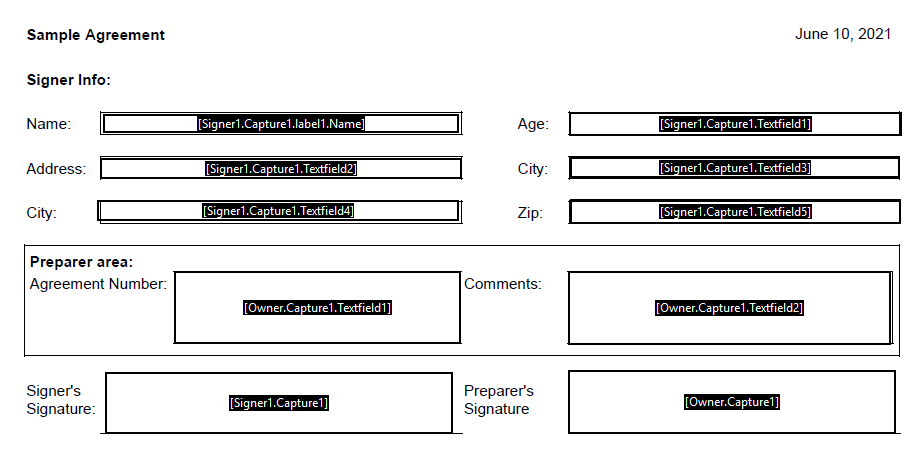
As you can see, the two signers on the document will be Signer1 and Owner. These will be the custom IDs used in the code section below to let OneSpan Sign know what fields to associate with each signer.
Configuring Document Extraction
The sample code below shows you how to setup your transaction for document extraction. In each withSigner call, you will see that the custom IDs coincide with the ones in the image of the PDF form shown above.
Because the sender of the transaction will by default be added to the signer list with role name of Owner, you do not have to explicitly specify sender information in the withSigner call.
The .withDocument also has a call to enableExtraction.
Because this is done, you do not have to define the signature locations and who needs to sign the document. This is already taken care of with the IDs and the associated form field names from the PDF.
The following code will do this:
DocumentPackage superDuperPackage = PackageBuilder.newPackageNamed("Test Document Extraction")
.withSigner(SignerBuilder.newSignerWithEmail("[email protected]" )
.withCustomId("Signer1")
.withFirstName("John")
.withLastName("Smith"))
.withDocument(DocumentBuilder.newDocumentWithName("testDocumentExtraction")
.fromFile("path_to_pdf")
.enableExtraction())
.build();
PackageId packageId = eslClient.createPackageOneStep(superDuperPackage);
eslClient.sendPackage(packageId);
Results
The required fields are highlighted for the user to fill out. The Name field will be filled in automatically by OneSpan Sign when the signing is complete. Likewise, the owner will also see their designated fields highlighted to fill out.
To download the full code sample see our Code Share site. The PDF used in this topic can be found here.
The document extraction feature automatically creates all signatures and fields that exist in an uploaded PDF file. The positions and sizes of the signatures and fields in the PDF file are automatically retained in OneSpan Sign.
Document Extraction Limitations
The following limitations affect Document Extraction:
-
Document Extraction is available only in the API call that uploads the document. It is not available in subsequent calls.
-
The following fields are not supported when using Document Extraction.
-
Radio buttons
-
List fields
-
Date fields
-
Custom fields
-
Text area
-
Configuring the PDF Form Fields
First, you will need a PDF with form fields, named in a way that OneSpan Sign can recognize them. For more information on the proper format of the form field names see the feature overview. The form field names on the fields are shown in the image below.
As you can see, the two signers on the document will be Signer1 and Owner. These will be the custom IDs used in the code section below to let OneSpan Sign know what fields to associate with each signer.
Configuring Document Extraction
The sample code below shows you how to setup your transaction for document extraction. In each withSigner call, you will see that the custom IDs coincide with the ones in the image of the PDF form shown above. The .withDocument also has a call to enableExtraction.
Because this is done, you do not have to define the signature locations and who needs to sign the document. This is already taken care of with the IDs and the associated form field names from the PDF.
The following code will do this:
DocumentPackage superDuperPackage = PackageBuilder.NewPackageNamed("Test Document Extraction")
.WithSigner(SignerBuilder.NewSignerWithEmail("[email protected]")
.WithCustomId("Signer1")
.WithFirstName("John")
.WithLastName("Smith"))
.WithDocument(DocumentBuilder.NewDocumentNamed("testDocumentExtraction")
.FromFile("C:\\Users\\liangdu1\\Desktop\\work\\documents\\610\\test_document_extraction.pdf")
.EnableExtraction())
.Build();
PackageId packageId = eslClient.CreatePackageOneStep(superDuperPackage);
eslClient.SendPackage(packageId);
Results
The required fields are highlighted for the user to fill out. The Name field will be filled in automatically by OneSpan Sign when the signing is complete. Likewise, the owner will also see their designated fields highlighted to fill out.
To download the full code sample see our Code Share site. The PDF used in this topic can be found here.
The document extraction feature automatically creates all signatures and fields that exist in an uploaded PDF file. The positions and sizes of the signatures and fields in the PDF file are automatically retained in OneSpan Sign.
Document Extraction Limitations
The following limitations affect Document Extraction:
-
Document Extraction is available only in the API call that uploads the document. It is not available in subsequent calls.
-
The following fields are not supported when using Document Extraction.
-
Radio buttons
-
List fields
-
Date fields
-
Custom fields
-
Text area
-
Configuring the PDF Form Fields
First, you will need a PDF with form fields, named in a way that OneSpan Sign can recognize them. For more information on the proper format of the form field names see the feature overview. The form field names on the fields are shown in the image below.
As you can see, the two signers on the document will be Signer1 and Owner. These will be the custom IDs used in the code section below to let OneSpan Sign know what fields to associate with each signer. By default, the values used for the role of the extraction tag/fieldName are Signer1 , Signer2 , and so on. If you want to include the sender of the transaction as a signer, use the tag Owner.
Configuring Document Extraction
Typically, you will build your JSON string dynamically, versus having a giant static string, like this. This is to give a good representation of the structure of the JSON you will need to create your transaction properly.
The JSON below is formatted for readability. In each roles object, you will see that the custom IDs coincide with the ones in the image of the PDF form shown above. The documents object also has extract to true.
Because this is done, you do not have to define the signature locations and who needs to sign the document. This is already taken care of with the IDs and the associated form field names from the PDF.
HTTP Request
POST /api/packages
HTTP Headers
Accept: application/json Content-Type: multipart/form-data Authorization: Basic api_key
Request Payload
------WebKitFormBoundary1bNO60n7FqP5WO4t
Content-Disposition: form-data; name="file"; filename="testDocumentExtraction.pdf"
Content-Type: application/pdf
%PDF-1.5
%µµµµ
1 0 obj
<>>>
endobj....
------WebKitFormBoundary1bNO60n7FqP5WO4t
Content-Disposition: form-data; name="payload"
{
"roles": [
{
"id": "Signer1",
"type": "SIGNER",
"signers": [
{
"firstName": "John",
"lastName": "Smith",
"email": "[email protected]",
"id": "Signer1"
}
],
"name": "Signer1"
}
],
"documents": [
{
"name": "testDocumentExtraction",
"extract": true
}
],
"name": "Test Document Extraction",
"type": "PACKAGE",
"autoComplete": true,
"status": "SENT"
}
------WebKitFormBoundary1bNO60n7FqP5WO4t--
For a complete description of each field, see the Request Payload table below.
Response Payload
{ "id": "9sKhW-h-qS9m6Ho3zRv3n2a-rkI=" }
Results
The required fields are highlighted for the user to fill out. The Name field will be filled in automatically by OneSpan Sign when the signing is complete. Likewise, the owner will also see their designated fields highlighted to fill out.
Request Payload Table
| Property | Type | Editable | Required | Default | Sample Values |
|---|---|---|---|---|---|
| status | string | Yes | No | DRAFT | DRAFT / SENT / COMPLETED / ARCHIVED / DECLINED / OPTED_OUT / EXPIRED |
| autoComplete | boolean | Yes | No | true | true / false |
| type | string | Yes | No | PACKAGE | PACKAGE / TEMPLATE / LAYOUT |
| name | string | Yes | Yes | n/a | Test Document Extraction |
| documents | |||||
| name | string | Yes | No | n/a | testDocumentExtraction |
| extract | boolean | Yes | No | false | true / false |
| roles | |||||
| id | string | Yes | No | n/a | Preparer1 |
| name | string | Yes | No | n/a | Sender |
| type | string | Yes | No | SIGNER | SIGNER / SENDER |
| signers | |||||
| string | Yes | Yes | n/a | [email protected] | |
| firstName | string | Yes | Yes | n/a | Michael |
| lastName | string | Yes | Yes | n/a | Williams |
| phone | string | Yes | No | n/a | 514-555-8888 |
| id | string | Yes | No | n/a | Preparer1 |
| delivery | |||||
| boolean | Yes | No | false | true / false | |
| provider | boolean | Yes | No | false | true / false |
| download | boolean | Yes | No | false | true / false |
To download the full code sample see our Code Share site. The PDF used in this topic can be found here.
The document extraction feature automatically creates all signatures and fields that exist in an uploaded PDF file. The positions and sizes of the signatures and fields in the PDF file are automatically retained in OneSpan Sign.
Document Extraction Limitations
The following limitations affect Document Extraction:
-
Document Extraction is available only in the API call that uploads the document. It is not available in subsequent calls.
-
The following fields are not supported when using Document Extraction.
-
Radio buttons
-
List fields
-
Date fields
-
Custom fields
-
Text area
-
Configuring the PDF Form Fields
First, you will need a PDF with form fields, named in a way that OneSpan Sign can recognize them. For more information on the proper format of the form field names see the feature overview. The form field names on the fields are shown in the image below.
As you can see, the two signers on the document will be Signer1 and Owner. These will be the custom IDs used in the code section below to let OneSpan Sign know what fields to associate with each signer.
Configuring Document Extraction
The sample code below shows you how to setup your transaction for document extraction. In each Role object, you will see that the name attributes coincide with the ones in the image of the PDF form shown above.
Because the sender of the transaction will by default be added to the signer list with the role name of Owner, you do not have to explicitly build a Role object for the sender.
In the Document object, the extract attribute is also set to true.
Because this is done, you do not have to define the signature locations and who needs to sign the document. This is already taken care of with the IDs and the associated form field names from the PDF.
ESignLiveSDK sdk = new ESignLiveSDK();
//Create package
ESignLiveAPIObjects.Package_x pkg = new ESignLiveAPIObjects.Package_x();
pkg.name = 'Test Document Extraction - ' + Datetime.now().format();
pkg.status = ESignLiveAPIObjects.PackageStatus.DRAFT;
//Create Roles
String roleId1 = 'Signer1';
ESignLiveAPIObjects.Role role1 = new ESignLiveAPIObjects.Role();
role1.signers = sdk.createRolesSigner('sigenr1_firstname', 'signer1_lastname', '[email protected]', 'CEO', 'ABC Bank');
role1.id = roleId1;
role1.name = roleId1;
pkg.roles = new List<ESignLiveAPIObjects.Role>{role1}; //add role
//Prepare Documents Blob
String document1Name = 'Sample_Document_Extraction';
StaticResource sr = [SELECT Id, Body FROM StaticResource WHERE Name = 'test_document_extraction' LIMIT 1];
Map<String,Blob> documentBlobMap = new Map<String,Blob>();
documentBlobMap.put(document1Name, sr.Body);
//Create Document Metadata
ESignLiveAPIObjects.Document document1 = new ESignLiveAPIObjects.Document();
document1.name = document1Name;
document1.id = document1Name;
document1.extract = true;
pkg.documents = new List<ESignLiveAPIObjects.Document>{document1}; //add document
//Send package One Step
String packageId = sdk.createPackage(pkg,documentBlobMap);
System.debug('PackageId: ' + packageId);
Results
The required fields are highlighted for the user to fill out. The Name field will be filled in automatically by OneSpan Sign when the signing is complete. Likewise, the owner will also see their designated fields highlighted to fill out.