Document Extraction recherche les signatures et les champs portant un nom approprié dans un document PDF téléversé, et pour chacun d'eux, il crée une signature ou un champ OneSpan Sign. Les positions et les tailles des signatures et des champs du PDF sont automatiquement conservées dans OneSpan Sign.
Les informations nécessaires pour créer chaque signature ou champ OneSpan Sign sont tirées du nom de la signature ou du champ PDF.
Limites de l'extraction de documents
Les limitations suivantes affectent l'extraction de documents :
-
L'extraction de documents n'est disponible que dans l'appel API qui téléverse le document. Il n'est pas disponible lors des appels suivants.
-
Les champs suivants ne sont pas pris en charge lors de l'utilisation de l'extraction de documents.
-
Boutons radio
-
Champs de la liste
-
Champs de la date
-
Champs personnalisés
-
Zone de texte
-
Conventions d'appellation
Pour créer un champ de signature OneSpan Sign, le champ PDF doit avoir un nom de la forme [Signer.SigStyle#] où :
Signer: Par défaut, les valeurs utilisées pour le rôle de la balise d'extraction/du nom du champ sont les suivantes Signer1, Signer2 et ainsi de suite. Si vous souhaitez inclure l'expéditeur de la transaction en tant que signataire, utilisez la balise Owner. Si vous spécifiez un ID de rôle personnalisé pour vos destinataires, vous utiliserez cette valeur dans vos balises.SigStyle#: Style de signature (Capture, Initials,Fullname, or Mobile Capture) combiné avec un entier pour l'unicité. Par exemple : Capture1 ou Fullname09.
Si vous souhaitez que le champ de signature soit facultatif, il suffit d'utiliser le format suivant : [Signer.SigStyle#.Optional].
Pour créer un champ OneSpan Sign non lié, le champ PDF doit avoir un nom de la forme [Signer.SigStyle#.FieldStyle#] où :
Signer.SigStyle#identifie la signature associée à ce champ.FieldStyle#est un style de champ (Textfield ou Checkbox) combiné à un nombre entier pour l'unicité, par exemple : Textfield2 ou Checkbox6.
Pour créer un champ OneSpan Sign lié, le champ PDF doit avoir un nom de la forme [Signer.SigStyle#.label#.Binding] où :
Signer.SigStyle#identifie la signature associée à ce champ.label#est un identifiant du champ, constitué du mot label combiné à un nombre entier pour l'unicité.-
Bindingest un style de champ. Les valeurs possibles sont Date ou {approval.signed} Name ou {signer.name} Title ou {signer.title} et Company ou {signer.company}. Les deux membres de chaque paire signifient le même style de champ.
Toutes les parties d'un nom de champ PDF sont comparées en utilisant des correspondances insensibles à la casse. Par exemple, un champ nommé [Signer1.Fullname1.label1.Date] est traité de la même manière qu'un champ nommé [Signer1.FULLNAME1.LABEL1.DATE]. Les noms des champs sont alphanumériques. Ils ne peuvent pas contenir de caractères spéciaux autres que le trait de soulignement (_).
Exemple
Voici un exemple. Supposons qu'un paquet ait deux signataires dont les ID personnalisés sont les suivants Signer1 et Owner. Supposons également que l'extraction soit activée et qu'un PDF soit téléchargé avec des champs portant les noms suivants :
[Owner.Fullname1] [Owner.Fullname1.label1.Date] [Owner.Fullname1.Textfield1] [Owner.Fullname1.Checkbox1] [Owner.Fullname2.Optional]
[Signer1.Capture1][Signer1.Capture1.label1.Name][Signer1.Capture1.label2.Date][Signer1.Capture1.label3.Title][Signer1.Initials1][Signer1.Initials2]
Avant de signer, Owner doit remplir deux champs :
[Owner.Fullname1.Textfield1][Owner.Fullname1.Checkbox1]
Une fois que ces champs sont remplis, Owner peut signer [Owner.Fullname1] et [Owner.Fullname1.label1.Date] sera automatiquement rempli avec la date de la signature.
Signer1 doit signer à trois endroits :
[Signer1.Initials1][Signer1.Initials2][Signer1.Capture1]
Une fois que tous ces documents auront été signés, les champs restants seront remplis :
[Signer1.Capture1.label1.Name][Signer1.Capture1.label2.Date][Signer1.Capture1.label3.Title]
Si vous avez spécifié des identifiants personnalisés pour l'expéditeur et le signataire (par exemple, Agent1 et Client1), utilisez des noms de champs de formulaire similaires à ceux ci-dessous et le flux de signature restera le même :
[Agent1.Fullname1] [Client1.Initials1]
Autres méthodes d'extraction
Vous pouvez également être intéressé par nos autres types d'extraction :
Pour télécharger l'exemple complet de code, consultez notre site Partage de code. Le PDF utilisé dans cette rubrique se trouve ici.
La fonction d'extraction de documents crée automatiquement toutes les signatures et tous les champs qui existent dans un fichier PDF téléversé. Les positions et les tailles des signatures et des champs dans le fichier PDF sont automatiquement conservées dans OneSpan Sign.
Limites de l'extraction de documents
Les limitations suivantes affectent l'extraction de documents :
-
L'extraction de documents n'est disponible que dans l'appel API qui téléverse le document. Il n'est pas disponible lors des appels suivants.
-
Les champs suivants ne sont pas pris en charge lors de l'utilisation de l'extraction de documents.
-
Boutons radio
-
Champs de la liste
-
Champs de la date
-
Champs personnalisés
-
Zone de texte
-
Configuration des champs du formulaire PDF
Tout d'abord, vous aurez besoin d'un PDF avec des champs de formulaire, nommés de manière à ce que OneSpan Sign puisse les reconnaître. Pour obtenir plus d'informations sur le bon format des noms des champs du formulaire, consultez la rubrique présentation de la fonctionnalité. Les noms des champs du formulaire sont indiqués dans l'image ci-dessous.
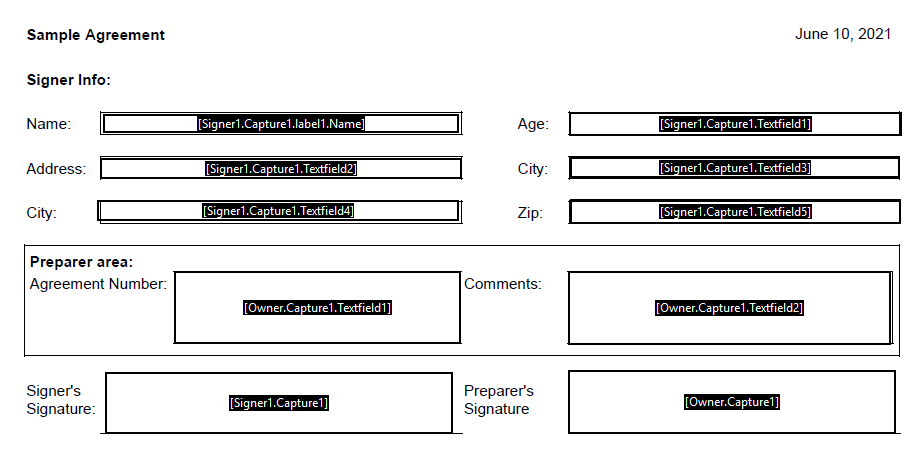
Comme vous pouvez le voir, les deux signataires du document seront Signataire1 et Propriétaire. Il s'agit des ID personnalisés utilisés dans la section du code ci-dessous pour indiquer à OneSpan Sign les champs à associer à chaque signataire.
Configuration de l'extraction de documents
L'exemple de code ci-dessous vous montre comment configurer votre transaction pour l'extraction de documents. Dans chaque appel withSigner, vous verrez que les ID personnalisés coïncident avec ceux de l'image du formulaire PDF présentée ci-dessus.
Étant donné que l'expéditeur de la transaction sera ajouté par défaut à la liste des signataires avec un nom de rôle de Owner vous n'avez pas besoin de spécifier explicitement les informations relatives à l'expéditeur dans l'appel withSigner.
Le .withDocument comporte également un appel à enableExtraction.
Comme cela est fait, vous n'avez pas à définir les emplacements de signature et les personnes qui doivent signer le document. Les ID et les noms des champs de formulaire associés du PDF s'en chargent déjà.
Le code suivant permet d'effectuer ce qui suit :
DocumentPackage superDuperPackage = PackageBuilder.newPackageNamed("Test Document Extraction")
.withSigner(SignerBuilder.newSignerWithEmail("[email protected]" )
.withCustomId("Signer1")
.withFirstName("John")
.withLastName("Smith"))
.withDocument(DocumentBuilder.newDocumentWithName("testDocumentExtraction")
.fromFile("path_to_pdf")
.enableExtraction())
.build();
PackageId packageId = eslClient.createPackageOneStep(superDuperPackage);
eslClient.sendPackage(packageId);
Résultats
Les champs obligatoires sont mis en évidence pour que l'utilisateur les remplisse. Le champ Nom sera rempli automatiquement par OneSpan Sign lorsque la signature sera terminée. De même, le propriétaire verra également ses champs désignés mis en évidence pour les remplir.
Pour télécharger l'exemple complet de code, consultez notre site Partage de code. Le PDF utilisé dans cette rubrique se trouve ici.
La fonction d'extraction de documents crée automatiquement toutes les signatures et tous les champs qui existent dans un fichier PDF téléversé. Les positions et les tailles des signatures et des champs dans le fichier PDF sont automatiquement conservées dans OneSpan Sign.
Limites de l'extraction de documents
Les limitations suivantes affectent l'extraction de documents :
-
L'extraction de documents n'est disponible que dans l'appel API qui téléverse le document. Il n'est pas disponible lors des appels suivants.
-
Les champs suivants ne sont pas pris en charge lors de l'utilisation de l'extraction de documents.
-
Boutons radio
-
Champs de la liste
-
Champs de la date
-
Champs personnalisés
-
Zone de texte
-
Configuration des champs du formulaire PDF
Tout d'abord, vous aurez besoin d'un PDF avec des champs de formulaire, nommés de manière à ce que OneSpan Sign puisse les reconnaître. Pour obtenir plus d'informations sur le bon format des noms des champs du formulaire, consultez la rubrique présentation de la fonctionnalité. Les noms des champs du formulaire sont indiqués dans l'image ci-dessous.
Comme vous pouvez le voir, les deux signataires du document seront Signataire1 et Propriétaire. Il s'agit des ID personnalisés utilisés dans la section du code ci-dessous pour indiquer à OneSpan Sign les champs à associer à chaque signataire.
Configuration de l'extraction de documents
L'exemple de code ci-dessous vous montre comment configurer votre transaction pour l'extraction de documents. Dans chaque appel withSigner, vous verrez que les ID personnalisés coïncident avec ceux de l'image du formulaire PDF présentée ci-dessus. Le .withDocument comporte également un appel à enableExtraction.
Comme cela est fait, vous n'avez pas à définir les emplacements de signature et les personnes qui doivent signer le document. Les ID et les noms des champs de formulaire associés du PDF s'en chargent déjà.
Le code suivant permet d'effectuer ce qui suit :
DocumentPackage superDuperPackage = PackageBuilder.NewPackageNamed("Test Document Extraction")
.WithSigner(SignerBuilder.NewSignerWithEmail("[email protected]")
.WithCustomId("Signer1")
.WithFirstName("John")
.WithLastName("Smith"))
.WithDocument(DocumentBuilder.NewDocumentNamed("testDocumentExtraction")
.FromFile("C:\\Users\\liangdu1\\Desktop\\work\\documents\\610\\test_document_extraction.pdf")
.EnableExtraction())
.Build();
PackageId packageId = eslClient.CreatePackageOneStep(superDuperPackage);
eslClient.SendPackage(packageId);
Résultats
Les champs obligatoires sont mis en évidence pour que l'utilisateur les remplisse. Le champ Nom sera rempli automatiquement par OneSpan Sign lorsque la signature sera terminée. De même, le propriétaire verra également ses champs désignés mis en évidence pour les remplir.
Pour télécharger l'exemple complet de code, consultez notre site Partage de code. Le PDF utilisé dans cette rubrique se trouve ici.
La fonction d'extraction de documents crée automatiquement toutes les signatures et tous les champs qui existent dans un fichier PDF téléversé. Les positions et les tailles des signatures et des champs dans le fichier PDF sont automatiquement conservées dans OneSpan Sign.
Limites de l'extraction de documents
Les limitations suivantes affectent l'extraction de documents :
-
L'extraction de documents n'est disponible que dans l'appel API qui téléverse le document. Il n'est pas disponible lors des appels suivants.
-
Les champs suivants ne sont pas pris en charge lors de l'utilisation de l'extraction de documents.
-
Boutons radio
-
Champs de la liste
-
Champs de la date
-
Champs personnalisés
-
Zone de texte
-
Configuration des champs du formulaire PDF
Tout d'abord, vous aurez besoin d'un PDF avec des champs de formulaire, nommés de manière à ce que OneSpan Sign puisse les reconnaître. Pour obtenir plus d'informations sur le bon format des noms des champs du formulaire, consultez la rubrique présentation de la fonctionnalité. Les noms des champs du formulaire sont indiqués dans l'image ci-dessous.
Comme vous pouvez le voir, les deux signataires du document seront Signataire1 et Propriétaire. Il s'agit des ID personnalisés utilisés dans la section du code ci-dessous pour indiquer à OneSpan Sign les champs à associer à chaque signataire. Par défaut, les valeurs utilisées pour l'extraction balise/nomChamp sont Signataire1 , Signataire2 , et ainsi de suite. Si vous souhaitez inclure l'expéditeur de la transaction en tant que signataire, utilisez la balise Propriétaire.
Configuration de l'extraction de documents
En général, vous construisez votre chaîne JSON de manière dynamique, plutôt que d'avoir une chaîne statique géante, comme celle-ci. Il s'agit de donner une bonne représentation de la structure du JSON dont vous aurez besoin pour créer correctement votre transaction.
Le JSON ci-dessous est formaté pour être lisible. Dans chaque objet de rôle, vous verrez que les ID personnalisés coïncident avec ceux de l'image du formulaire PDF présentée ci-dessus. L'objet documents a également extract à vrai.
Comme cela est fait, vous n'avez pas à définir les emplacements de signature et les personnes qui doivent signer le document. Les ID et les noms des champs de formulaire associés du PDF s'en chargent déjà.
Requête HTTP
POST /api/packages
En-têtes HTTP
Accept: application/json Content-Type: multipart/form-data Authorization: Basic api_key
Données utiles de la demande
------WebKitFormBoundary1bNO60n7FqP5WO4t
Content-Disposition: form-data; name="file"; filename="testDocumentExtraction.pdf"
Content-Type: application/pdf
%PDF-1.5
%µµµµ
1 0 obj
<>>>
endobj....
------WebKitFormBoundary1bNO60n7FqP5WO4t
Content-Disposition: form-data; name="payload"
{
"roles": [
{
"id": "Signer1",
"type": "SIGNER",
"signers": [
{
"firstName": "John",
"lastName": "Smith",
"email": "[email protected]",
"id": "Signer1"
}
],
"name": "Signer1"
}
],
"documents": [
{
"name": "testDocumentExtraction",
"extract": true
}
],
"name": "Test Document Extraction",
"type": "PACKAGE",
"autoComplete": true,
"status": "SENT"
}
------WebKitFormBoundary1bNO60n7FqP5WO4t--
Pour une description complète de chaque champ, voir le tableau des données utiles de la demande ci-dessous.
Données utiles de la réponse
{ "id": "9sKhW-h-qS9m6Ho3zRv3n2a-rkI=" }
Résultats
Les champs obligatoires sont mis en évidence pour que l'utilisateur les remplisse. Le champ Nom sera rempli automatiquement par OneSpan Sign lorsque la signature sera terminée. De même, le propriétaire verra également ses champs désignés mis en évidence pour les remplir.
Tableau des données utiles de la demande
| Propriété | Type | Modifiable | Requis | Par défaut | Exemples de valeurs |
|---|---|---|---|---|---|
| statut | chaîne de caractères | Oui | Non | ÉBAUCHE | ÉBAUCHE / ENVOYÉ / COMPLÉTÉ / ARCHIVÉ / DÉCLINÉ / REFUSÉ / EXPIRÉ |
| ComplétionAuto | booléen | Oui | Non | vrai | vrai / faux |
| type | chaîne de caractères | Oui | Non | PACKAGE | PAQUET / MODÈLE / MISE EN PAGE |
| nom | chaîne de caractères | Oui | Oui | s.o. | Extraction de documents de test |
| documents | |||||
| nom | chaîne de caractères | Oui | Non | s.o. | testDocumentExtraction |
| extrait | booléen | Oui | Non | faux | vrai / faux |
| rôles | |||||
| id | chaîne de caractères | Oui | Non | s.o. | Préparateur1 |
| nom | chaîne de caractères | Oui | Non | s.o. | Expéditeur |
| type | chaîne de caractères | Oui | Non | SIGNER | SIGNATAIRE / EXPÉDITEUR |
| signataires | |||||
| courriel | chaîne de caractères | Oui | Oui | s.o. | courriel.pré[email protected] |
| Prénom | chaîne de caractères | Oui | Oui | s.o. | Michael |
| Nom de famille | chaîne de caractères | Oui | Oui | s.o. | Williams |
| téléphone | chaîne de caractères | Oui | Non | s.o. | 514-555-8888 |
| id | chaîne de caractères | Oui | Non | s.o. | Préparateur1 |
| livraison | |||||
| courriel | booléen | Oui | Non | faux | vrai / faux |
| fournisseur | booléen | Oui | Non | faux | vrai / faux |
| télécharger | booléen | Oui | Non | faux | vrai / faux |
Pour télécharger l'exemple complet de code, consultez notre site Partage de code. Le PDF utilisé dans cette rubrique se trouve ici.
La fonction d'extraction de documents crée automatiquement toutes les signatures et tous les champs qui existent dans un fichier PDF téléversé. Les positions et les tailles des signatures et des champs dans le fichier PDF sont automatiquement conservées dans OneSpan Sign.
Limites de l'extraction de documents
Les limitations suivantes affectent l'extraction de documents :
-
L'extraction de documents n'est disponible que dans l'appel API qui téléverse le document. Il n'est pas disponible lors des appels suivants.
-
Les champs suivants ne sont pas pris en charge lors de l'utilisation de l'extraction de documents.
-
Boutons radio
-
Champs de la liste
-
Champs de la date
-
Champs personnalisés
-
Zone de texte
-
Configuration des champs du formulaire PDF
Tout d'abord, vous aurez besoin d'un PDF avec des champs de formulaire, nommés de manière à ce que OneSpan Sign puisse les reconnaître. Pour obtenir plus d'informations sur le bon format des noms des champs du formulaire, consultez la rubrique présentation de la fonctionnalité. Les noms des champs du formulaire sont indiqués dans l'image ci-dessous.
Comme vous pouvez le voir, les deux signataires du document seront Signataire1 et Propriétaire. Il s'agit des ID personnalisés utilisés dans la section du code ci-dessous pour indiquer à OneSpan Sign les champs à associer à chaque signataire.
Configuration de l'extraction de documents
L'exemple de code ci-dessous vous montre comment configurer votre transaction pour l'extraction de documents. Dans chaque Role , vous verrez que les attributs du nom coïncident avec ceux de l'image du formulaire PDF présentée ci-dessus.
Comme l'expéditeur de la transaction sera ajouté par défaut à la liste des signataires avec le nom de rôle Propriétaire, il n'est pas nécessaire de construire explicitement un objet Role pour l'expéditeur.
Dans l'objet Document , l'attribut extract est également défini comme vrai.
Comme cela est fait, vous n'avez pas à définir les emplacements de signature et les personnes qui doivent signer le document. Les ID et les noms des champs de formulaire associés du PDF s'en chargent déjà.
ESignLiveSDK sdk = new ESignLiveSDK();
//Create package
ESignLiveAPIObjects.Package_x pkg = new ESignLiveAPIObjects.Package_x();
pkg.name = 'Test Document Extraction - ' + Datetime.now().format();
pkg.status = ESignLiveAPIObjects.PackageStatus.DRAFT;
//Create Roles
String roleId1 = 'Signer1';
ESignLiveAPIObjects.Role role1 = new ESignLiveAPIObjects.Role();
role1.signers = sdk.createRolesSigner('sigenr1_firstname', 'signer1_lastname', '[email protected]', 'CEO', 'ABC Bank');
role1.id = roleId1;
role1.name = roleId1;
pkg.roles = new List<ESignLiveAPIObjects.Role>{role1}; //add role
//Prepare Documents Blob
String document1Name = 'Sample_Document_Extraction';
StaticResource sr = [SELECT Id, Body FROM StaticResource WHERE Name = 'test_document_extraction' LIMIT 1];
Map<String,Blob> documentBlobMap = new Map<String,Blob>();
documentBlobMap.put(document1Name, sr.Body);
//Create Document Metadata
ESignLiveAPIObjects.Document document1 = new ESignLiveAPIObjects.Document();
document1.name = document1Name;
document1.id = document1Name;
document1.extract = true;
pkg.documents = new List<ESignLiveAPIObjects.Document>{document1}; //add document
//Send package One Step
String packageId = sdk.createPackage(pkg,documentBlobMap);
System.debug('PackageId: ' + packageId);
Résultats
Les champs obligatoires sont mis en évidence pour que l'utilisateur les remplisse. Le champ Nom sera rempli automatiquement par OneSpan Sign lorsque la signature sera terminée. De même, le propriétaire verra également ses champs désignés mis en évidence pour les remplir.